- why deterministic workflows usually create more value than vague prompting
- how context, format, and scope control improve the quality of AI output
- why verification matters more than benchmark scores in real-world use
According to ChatGPT, I was in the top 1% of its worldwide users in 2025. Its own description of my profile was blunt: this was power-user, professional-grade usage built around thinking, drafting, and systems work rather than entertainment.
That is less interesting as a statistic than as a prompt for reflection. After a year of heavy use, some patterns became clear. These are the lessons that mattered most.
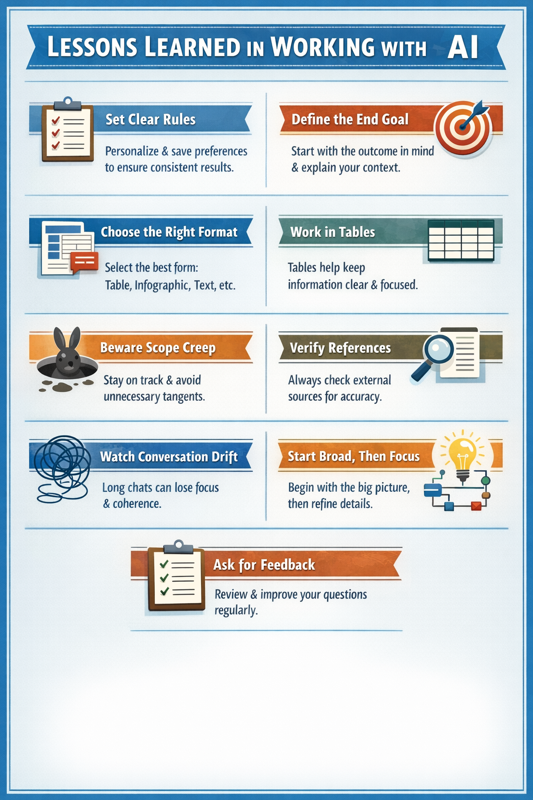
Lessons From a Year of Serious AI Use
1. Deterministic beats vague
The closer you are to working in a deterministic rather than probabilistic way, the better results you get. Set the rules up front so the model knows how to behave. Personalise it where memory is available. Consistency compounds when you want to work at speed.
2. Start with the end goal
Explain the context and the outcome you want. Is the model helping you think, review, generate possibilities, summarise, or explain? The better the goal is defined, the more useful the output becomes.
3. Match the form to the task
Think about the form of the answer before you ask for it. Some problems are better handled as a table, some as a short framework, some as bullets, and some as prose. The wrong output shape often creates avoidable confusion.
4. Tables often improve thinking
A lot of output becomes easier to understand in table form. Tables help compare dimensions, narrow scope, and reduce the chance of drifting into loosely connected ideas.
5. Scope creep is real
AI will often try to guess beyond what you asked. That can feel helpful, but it can also introduce embellishment before the primary question is answered. Keep the task bounded.
6. Benchmarks do not equal trust
Most AI benchmarks do not reflect real-world use. A model can score well and still fail at something basic such as getting a reference right. For important work, verification matters more than the benchmark headline.
7. Long conversations drift
Long-form conversations become less accurate over time. Alongside scope creep, there is coherence creep. The longer the thread, the greater the risk of losing the original frame or corrupting the memory trail.
8. Start broad, then go narrow
When complexity is high, begin with architecture and model first, then move into instructions and detailed tasks. It helps to agree the high-level map before pushing into execution.
9. Ask for feedback on your own use
After enough usage, your working style becomes visible to the model. That makes it possible to ask for feedback on how to improve your prompts, your framing, and your questions.
Infographic